
Im Zuge der Digitalisierung sehen sich Unternehmen zunehmend komplexeren und umfangreicheren IT-Systemen zur Unterstützung ihrer Geschäftsprozesse konfrontiert. Daten und Informationen sind zum kritischen Erfolgsfaktor für den erfolgreichen Geschäftsbetrieb geworden und bilden die Basis von technologischen Trends wie Industrie 4.0.

Das steigende Datenwachstum bietet für Unternehmen neue Potenziale zur Realisierung von Geschäftsmodellen und zum systematischen Lernen aus den Daten für schnellere sowie bessere Entscheidungs- und Anpassungsprozesse. Hierfür dürfen Daten jedoch nicht nur gesammelt, sondern müssen zu höherwertigen Informationen aufbereitet und in Entscheidungen überführt werden. Essentiell wird dabei die Fähigkeit zur automatischen Datenanalyse, um Ursache-Wirkungsbeziehungen aus Daten verschiedener Quellen abzuleiten und zukünftige Ereignisse zu prognostizieren.
Trotz der gesteigerten Sensibilisierung für die Bedeutung von Daten, wird das Thema der Datenqualität im Unternehmen jedoch oftmals vernachlässigt. Studien zufolge haben nur ca. 40% der Unternehmen (klar) definierte Strukturen und Prozesse im Stammdatenmanagement. Zwar hat ein Großteil der Unternehmen bereits einzelne Stammdatenprojekte durchgeführt, jedoch keine kontinuierlichen Maßnahmen etabliert. Insbesondere die mangelnde Verfügbarkeit interner Ressourcen wird hierfür als Grund genannt (Schuh et al. 2014). Eine Hauptursache dafür ist, dass schlechte Datenqualität erfahrungsgemäß nicht unmittelbar zum Stillstand eines Unternehmens führt, sondern dass die Prozesse schleichend durch zusätzliche Abstimmungen und Rückfragen immer ineffizienter und ineffektiver werden. Organisationale und kulturelle Auswirkungen gehen damit ebenfalls im Unternehmen einher, indem das Vertrauen in die Daten und IT-Systeme abnimmt. Das eigentliche Potenzial der Digitalisierung im Unternehmen kann nicht realisiert werden und wirkt sich durch die zunehmende IT-Abhängigkeit überproportional negativ auf das Unternehmen aus.
Um der Herausforderung mangelhafter Stammdatenqualität im Unternehmen zu begegnen, ist ein integriertes Stammdatenmanagement unerlässlich. Neben technischen Aspekten sind hierbei kulturelle und organisationale Aspekte von großer Bedeutung. So ist die Unterstützung durch das Management sowie die Beteiligung der IT-Abteilung und der Fachbereiche für den nachhaltigen Erfolg von Stammdatenprojekten notwendig. Ebenso muss das Stammdatenmanagement in der IT-Strategie des Unternehmens verankert werden, um so ein Bewusstsein für die Relevanz dieses Themas zu schaffen. Weiterhin muss sichergestellt werden, dass das Fachwissen der verschiedenen Abteilungen – auch werksübergreifend – durch die Stammdatenstruktur abgebildet und ein vorher definierter Qualitätsstandard eingehalten wird. Zu diesem Zweck sind vor allem organisatorische Strukturen – wie Zuständigkeiten für die Datenpflege und entsprechende Pflegeprozesse – zu definieren. Eine geeignete Datenqualitätssoftware bietet dabei das notwendige Handwerkszeug für das Stammdatenmanagement, um die Datenqualität im Unternehmen gemäß dem „Fit-For-Use“-Ansatz zu schaffen und zu erhalten.
Grundlagen zur Stammdatenqualität praxisorientiert
Stammdaten bilden die Grundlage der digitalen Wirtschaft und sind für das digital vernetzte Unternehmen von essentieller Bedeutung (Otto und Österle 2016). Das Erreichen und die Sicherstellung eines angemessenen Maßes an Stammdatenqualität ist eine kritische Voraussetzung für eine effiziente und effektive unternehmensübergreifende Zusammenarbeit (Schäffer und Stelzer 2017).
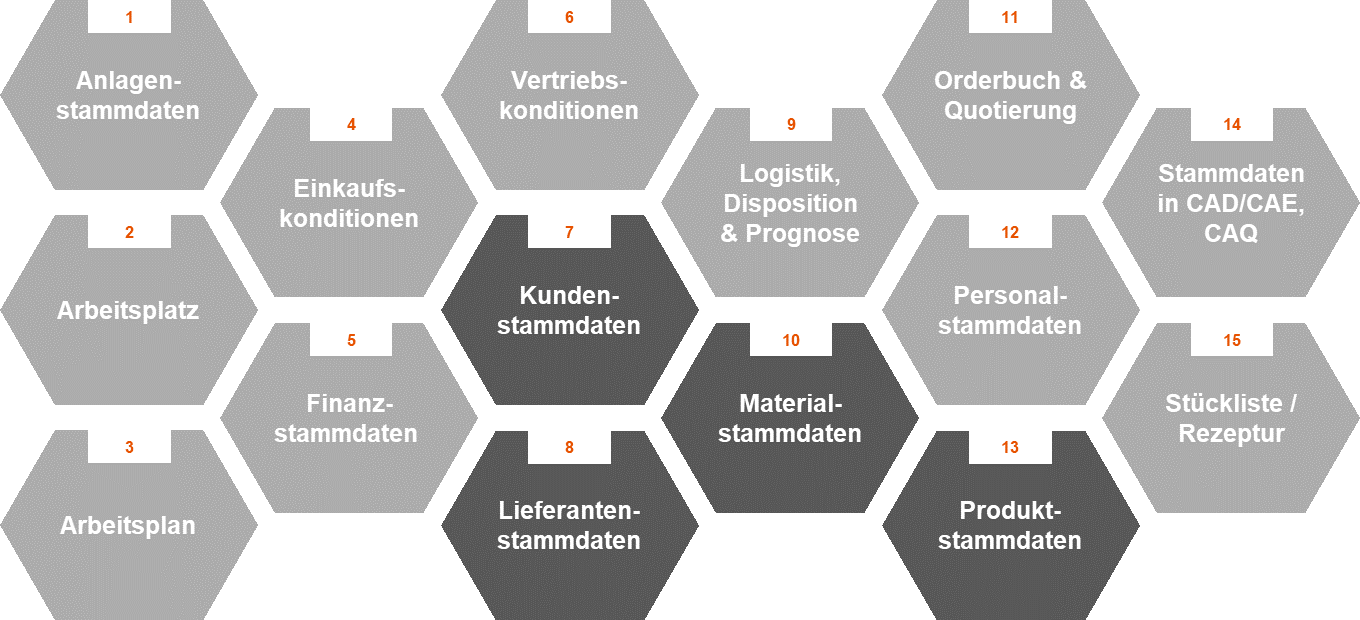
Stammdaten beschreiben kritische Geschäftsobjekte eines Unternehmens und bezeichnen Produkte, Lieferanten, Kunden, Mitarbeiter bzw. ähnliche Gegenstände, die nur selten Änderungen erfahren. Ein Stammdatenobjekt ist ein spezielles Datenobjekt, dessen Attributwerte (Datenelemente) sich im Vergleich zu anderen Datenobjekten (z. B. Bewegungsdatenobjekten) seltener ändern (Otto und Österle 2016). Ein Stammdatenobjekt wird durch die Struktur (Bauplan) und das Verhalten (Funktionen und Regelwerk) beschrieben (Scheuch et al. 2012). Abbildung 1 zeigt 15 Stammdatenobjekte, die im Rahmen einer umfangreichen Literaturanalyse identifiziert werden konnten.
Im Kontext von Datenqualität werden Daten zumeist als einfache Fakten bzw. als „Rohstoff“ interpretiert, wohingegen unter Information Daten in einem bestimmten Kontext verstanden werden. Daten sind somit die Basis für Informationen, die wiederum Grundlage für Entscheidungen sind (Schäffer und Stelzer 2018). Als pragmatische Definition der Datenqualität schlägt Hildebrand et al. (2015) vor „… Datenqualität ist die Gesamtheit der Ausprägungen von Qualitätsmerkmalen eines Datenbestandes bezüglich dessen Eignung, festgelegte und vorausgesetzte Erfordernisse zu erfüllen.“ Datenqualität ist somit ein Maß für die Eignung der Daten für spezifische Anforderungen in Geschäftsprozessen, in denen sie verwendet werden. Die Datenqualität ist ein mehrdimensionales, kontextuelles Konzept, da es nicht mit einer einzigen Funktion beschrieben werden kann, sondern auf der Basis verschiedener Datenqualitätsdimensionen und Metriken (Otto und Österle 2016). Typische, häufig in der Praxis verwendete Qualitätsdimensionen sind: Vollständigkeit, Aktualität, Genauigkeit, Korrektheit und Konsistenz. Die Datenqualität wird deshalb oft mit dem Begriff “fitness for use” assoziiert (Wang und Strong 1996).
Im europäischen Wirtschaftsraum stellt die seit ihrer Einführung 1987 mehrfach revidierte internationale Normenfamilie ISO 9000 ff. einen wichtigen Standard für Qualitätsmanagementsysteme (QMS) dar. Diese umfassen die Funktionen: Qualitätsplanung, Qualitätslenkung, Qualitätssicherung und Qualitätsverbesserung. Überträgt man die Anforderung der ISO 9001 auf das Datenqualitätsmanagement, so umfasst das Datenqualitätsmanagement (DQM) aufeinander abgestimmte Tätigkeiten zum Leiten und Lenken einer Unternehmensorganisation bzgl. der Datenqualität. Technisch betrachtet ist das Datenqualitätsmanagement das qualitätsorientierte Datenmanagement und umfasst die Modellierung, Erzeugung, Verarbeitung, Speicherung und Darstellung von Daten mit dem Ziel der Sicherstellung einer möglichst hohen Datenqualität.
Vorgehensmodell zur Bewertung der Stammdatenqualität im Unternehmen
Stammdaten sind eine wesentliche Unternehmensressource, der eine immer stärkere Bedeutung zukommt. Insbesondere für eine optimale Unterstützung unternehmerischer Prozesse und der damit einhergehenden Nutzung von Rationalisierungspotenzialen sind Stammdaten mit „guter“ Qualität unabdingbar. Dabei stellt sich einerseits die Frage, was denn „gute“ Stammdaten sind und andererseits, wie diese erzeugt werden können (Beckmann und Schäffer 2016). Bevor Unternehmen allerdings in die Phase der Optimierung ihrer Stammdaten einsteigen können, muss zunächst eine Bestandsaufnahme hinsichtlich der Stammdaten durchgeführt werden. Dazu dienen sogenannte Stammdaten Assessments (Schaeffer et al. 2018).
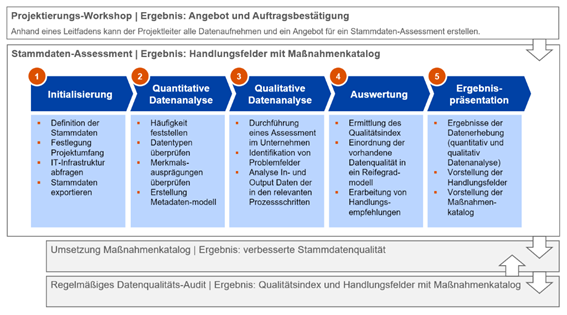
Zur Unterstützung solcher Stammdaten Assessments wurde im Rahmen der Forschungsinitiative DQC die DQC-Methodik für die Durchführung der Stammdaten Assessments sowie der Bewertung der Stammdatenqualität im Rahmen solcher Stammdaten Assessments entwickelt. Die Methodik basiert auf einem Best-of-Bread-Ansatz von über 20 Qualitätsmodellen zur Beurteilung der Datenqualität, wie z. B. AIMQ, EFQM-Qualitätsmodell, TDQM oder TdQM. Zielsetzung der DQC-Methodik ist es, eine einfache und ressourcenschonende Vorgehensweise insbesondere für Mittelstandsunternehmen bereitzustellen, mit deren Hilfe ein Datenqualitäts-Index berechnet und in regelmäßigen Abständen überprüft werden kann. Abbildung 2 zeigt die DQC-Methodik mit den fünf Phasen: (1) Initialisierung, (2) Quantitative Datenanalyse, (3) Qualitative Datenanalyse, (4) Auswertung und (5) Ergebnispräsentation.
Im Folgenden sind die Ergebnisse der einzelnen Phasen kurz aufgeführt:
- Phase 1: Das Ergebnis der Initialisierungsphase ist der Projektsteckbrief. Dieser enthält alle Informationen zur Konkretisierung des Projektes zur Bewertung der Stammdatenqualität im Unternehmen.
- Phase 2: Das Ergebnis der quantitativen Datenanalyse ist der quantitative Analysebericht. Dieser enthält die Ergebnisse aus der Datenanalyse aus Sicht der Attribute, Datensätze und Tabellen und beschreibt die indizierten Auffälligkeiten in den Stammdaten mit Beispielen. Ferner wird initial der unternehmensspezifische Stammdaten-Katalog erstellt und der DQ-Index berechnet.
- Phase 3: Das Ergebnis der qualitativen Datenanalyse ist der qualitative Analysebericht. Dieser enthält die Ergebnisse aus der Umfrage, qualitative Bewertung der Stammdatenqualität, Ursache-Wirkung von identifizierten Stammdatenfehlern und die finale Version des unternehmensspezifischen Stammdaten-Katalogs.
- Phase 4: Das Ergebnis der Auswertungsphase beinhaltet die Zusammenführung und Abgleich der Ergebnisse aus quantitativer und qualitativer Datenanalyse. Hieraus werden die Handlungsempfehlungen abgeleitet.
- Phase 5: Das Ergebnis der Präsentationsphase beinhaltet die Durchführung der Ergebnispräsentation aller Erkenntnisse und die Erarbeitung eines Maßnahmenkatalogs nach Dringlichkeit und Wertbeitrag gemeinsam mit dem Unternehmen.
Als zentrales Werkzeug der DQC-Methode dient u. a. der Stammdaten-Katalog (SDK). Der Stammdaten-Katalog wird während der Datenanalyse sukzessiv unternehmensspezifisch aufgebaut. Er beinhaltet die fachliche Stammdatenstruktur, die Attributsspezifikation, die Geschäftsregeln, etc. und unterstützt grundsätzlich den Aufbau eines unternehmensweiten Vokabulars. Ziel dabei ist die fachliche Beschreibung (Metadaten) aller Kernentitäten eines Unternehmens, insbesondere von Stammdatenobjekten, um ein einheitliches Verständnis im Unternehmen zu etablieren. Konkret dient der Stammdaten-Katalog als Grundlage für die Bewertung der vorliegenden Qualität, für die Zusammenführung, Dublettenprüfung und Harmonisierung der Stammdaten.
 Anzeige | kostenfreies Webinar der Trovarit Academy
Anzeige | kostenfreies Webinar der Trovarit Academy
Marktübersicht über Software-Lösungen für das Stammdatenmanagement
Stark unterschiedliche Funktionsumfänge machen die Auswahl von Lösungen für das Stammdatenmanagement komplex. Die nachfolgende Tabelle bietet dem Leser eine Übersicht verfügbarer Lösungen und zeigt, welche typischen Funktionsanforderungen durch die Softwareprodukte unterstützt werden.
Wichtige Software-Kategorien sind Datenintegration (DI), Datenqualität (DQ) und Stammdatenmanagement (MDM).
Produkte in der Kategorie Datenintegration (DI) unterstützen die Verteilung der Stammdaten in voneinander isolierte Applikationen. Dies beseitigt Redundanzen und Inkonsistenzen der Stammdaten und beinhaltet sechs Funktionsbereiche: Datenimport, Datentransformation, Datenexport, Datenaustausch, Datenhaltung und Konfliktbehandlung.
Produkte in der Kategorie Datenqualität (DQ) unterstützen die Sicherung der angemessenen Qualität. Dies steigert die Verlässlichkeit und Nutzbarkeit der Stammdaten und beinhaltet drei Funktionsbereiche: Datenanalyse, Datenanreicherung und Datenbereinigung.
Produkte in der Kategorie Stammdatenmanagement (MDM) schließlich unterstützen die Verwaltung im Rahmen des Lebenszyklus der Stammdatenobjekte und beinhalten drei Funktionsbereiche: Stammdatenanlage, Stammdatenpflege und Stammdatendeaktivierung.
Je nach Prägung unterstützen diese Produkte bestimmte Aufgaben. Ein Beispiel für einen Anwendungsfall ist die Bewertung der Qualität des Kunden-, Lieferanten – oder Artikelstamms. Einige Produkte bieten hierfür Funktionalität zur Erstellung gewichteter Regeln, anhand welcher ein Index generiert wird. Die zeitliche Entwicklung der Datenqualität wird dann übersichtlich in einem Report als Diagramm dargestellt. Ein weiteres Beispiel ist die regelbasierte Massendatenänderung. Durch Funktionalitäten wie Aufbau einer Regel ist es möglich auch Informationen im Freifeldtext gezielt zu manipulieren. Eine ausführlichere Darstellung enthält das White Paper „Stammdatenqualität im Zuge der Digitalisierung. Strategie, Methode und Werkzeuge für die Praxis.“
|
|
Whitepaper
Stammdatenqualität im Zuge der Digitalisierung Strategie, Methode und Werkzeuge für die Praxis |
| Autor: | DataQualityCenter | |
| Erschienen: | 2018-12-07 | |
| Schlagworte: | Datenmanagement, Datenqualität, Digitalisierung, Industrie 4.0, Master Data Management (MDM), Stammdatenmanagement | |
| Im Zuge der Digitalisierung sehen sich Unternehmen zunehmend mit komplexeren und umfangreicheren IT-Systemen zur Unterstützung ihrer Geschäftsprozesse konfrontiert. Daten und Informationen sind zum kritischen Faktor für den erfolgreichen Geschäftsbetrieb geworden und bilden die Basis von technologischen Trends wie Industrie 4.0. Obwohl eine gesteigerte Sensibilität für die Bedeutung von Daten spürbar ist, wird das Thema Datenqualität in vielen Unternehmen immer noch vernachlässigt. DataQualityCenter hat mit dem „Datenqualitäts-Assessment“ eine Methode entwickelt, mit dem die Ermittlung des Status Quo der Stammdatenqualität insbesondere auch für mittelständische Unternehmen mit vertretbarem Aufwand möglich ist. Abgerundet wird das Whitepaper durch einen Überblick darüber, wie Software bei der Bewertung und Verbesserung der Datenqualität unterstützen kann und was bei der Auswahl einer Datenmanagement-Software zu beachten ist. | ||
| Download | ||
Auswahlprozess für Software-Lösungen
Die Übersicht über vorhandene Software-Lösungen auf dem Markt zeigt deutlich, dass der Funktionsumfang der angebotenen Systeme sehr heterogen ist. Obwohl sich mit Master Data Management (MDM), Datenqualität (DQ) und Datenintegration (DI) durchaus grundlegende aufgabenorientierte Kategorien definieren lassen, halten sich Anbieter in der Regel nicht an diese starre Struktur. Vielmehr basiert das jeweils angebotene Softwarepaket aus einer Vielzahl einzelner funktionaler Module, mit denen der Anbieter den Kunden bestmöglich in von ihm vorgedachten Szenarien unterstützen will. Dies unterstreicht auch insbesondere die Marktübersicht, in der sich eine Vielzahl von untergeordneten Anwendungsfällen findet, für welche eine Software mehr oder weniger geeignet sein kann. Hinzu kommt, dass die Herausforderungen im Umgang mit Stammdaten und deren Qualität sehr unterschiedlich sein können. So hat beispielsweise ein Serienfertiger mit weltweiten Standorten und einer Vielzahl an betrieblichen Anwendungssystemen durchaus andere Herausforderungen als ein kleiner Werkzeugbauer, welcher insbesondere mit einer großen Teilevarianz umgehen muss. Auch eine direkte Anbindung an einen Onlineshop stellt eine völlig andere Anforderung an Stammdaten als ein projektbasiertes Auftragsgeschäft. Hieraus ergibt sich für den potenziellen Anwender die Herausforderung, das für die konkrete Unternehmenssituation passende Tool zu finden, mit dem das angestrebte Ziel bestmöglich unterstützt werden kann.
Drei-Phasen

Aus diesem Grund ist eine strukturierte Analyse des Bedarfs auf Basis der eigentlichen Geschäftsprozesse des Unternehmens unabdingbar. Das Vorgehen im Rahmen des bewährten 3PhasenKonzept, welches Unternehmen bereits seit Jahrzehnten bei der Auswahl eines an den Geschäftsprozessen orientierten ERP-Systems unterstützt, bietet sich auch im Kontext von Stammdatenqualität an. Das Konzept setzt sich aus der Analyse-, Auswahl- und Einführungsphase zusammen, die im Folgenden kurz beschrieben werden sollen.
In der Analysephase wird die aus der Perspektive eines vollständigen Stammdatenlebenszyklus die entscheidende Basis für die Auswahl eines passenden Systems getroffen. Alle Prozesse, die in Zusammenhang mit der später ausgewählten Software stehen, werden in dieser Phase analysiert und bei Bedarf auch neu konzipiert. Dies kann die Anlage von Stammdaten ebenso betreffen wie einmalige Qualitätsverbesserungsprojekte und den Umgang mit Stammdaten über den gesamten Lebenszyklus bis hin zur Archivierung. In diesem Zuge werden alle Stakeholder, also in diese Prozesse involvierte Personen und Organisationseinheiten, und die zugehörigen IT-Systeme identifiziert. Dies ist wichtig für die spätere Überleitung in Anforderungen an das System. Durch die Gestaltung verbesserter Soll-Prozesse wird zudem sichergestellt, dass die später ausgewählte Software die wesentlichen Kernanforderungen unterstützt und nicht durch organisationale und prozessuale Schwächen nur ineffektiv arbeiten kann.
Die Auswahlphase schließt sich an die Analyse an und hat nun zum Ziel, ein passendes System für die Anforderungen zu finden, die sich aus dem Stammdatenlebenszyklus ergeben. Dabei ist die Komplexität ab diesem Punkt sehr stark von den definierten Zielen des Systems abhängig. An dieser Stelle unterscheidet sich das Vorgehen wesentlich von dem bei der Auswahl anderer betrieblicher Anwendungssysteme. So kann diese Phase bereits mit der Sondierung von geeigneten Datenqualitätstools abgeschlossen sein. Solche Systeme sind häufig kompakte Stand-Alone-Software, für die ein aufwändiger Auswahlprozess nicht zielführend wäre. Soll hingegen das gesamte Stammdatenmanagement (MDM) eines Unternehmens mit vielen Einzelsystemen über eine Software gesteuert werden, ist durchaus eine detaillierte Erfassung der geforderten Funktionalitäten angebracht, um auf Basis eines Lastenhefts Anforderungen und Fähigkeiten der Systeme auf dem Markt vergleichen zu können.
Die Einführungsphase ist schließlich kritisch für den erfolgreichen Projektabschluss. An dieser Stelle muss wieder zwischen kleineren Stand-Alone-Systemen und größeren Software-Suiten unterschieden werden. Während nur bei letztgenannten der Vertragsverhandlung und originären Implementierungsbegleitung eine wesentliche Rolle zukommt, ist die Prozessoptimierung und Umsetzung der Ziele in Form von konkreter Übersetzung in das System in jedem Fall entscheidend für den Projekterfolg. Denn alle auf dem Markt verfügbaren Systeme unterstützen den Anwender zwar möglicherweise bei der Definition von Regeln, Analyse der Datenqualität oder Durchsetzung von Rollenmodellen im Stammdatenmanagement – keines der Systeme kann aber die Gestaltung eines effizienten Stammdatenkonzepts nach den oben genannten Zielen vollständig ersetzen.
Die Autoren:
Tobias Schöer, M.SC Bereich Produktionsmanagement und Lucas Wenger, MSc., Bereich Informationsmanagment, FIR e.V. an der RWTH Aachen
Dipl.-Inf. Thomas Schäffer und Prof. Dr. Helmut Beckmann, Kompetenzzentrum Unternehmenssoftware der Hochschule Heilbronn
Dipl.-Ing. Peter Treutlein und Alex Ron, B.Sc., Competence Center Datenmanagement der Trovarit AG
Literaturverzeichnis
Otto, B., and Österle, H. 2016. Corporate Data Quality: Voraussetzung erfolgreicher Geschäftsmodelle, Berlin, Heidelberg: Springer Berlin Heidelberg.
Hildebrand, K., Gebauer, M., Hinrichs, H., and Mielke, M. (eds.) 2015. Daten- und Informationsqualität: Auf dem Weg zur Information Excellence, Wiesbaden: Springer Fachmedien Wiesbaden.
Beckmann, H., and Schäffer, T. 2016. “Trends und Erfolgsfaktoren im Zuge der Digitalisierung: Ergebnisse einer Studie zum Stammdatenmanagement,” ERP Management (12:4), pp. 36–37.
Schäffer, T., Leyh, C., and Beckmann, H. 2018. “ALADDIN – Vorschlag eines Analyse- und Berechnungsmodells zur Investitionsbewertung für ein unternehmensweites Datenqualitätsmanagement,” in Multikonferenz Wirtschaftsinformatik (MKWI) 2018: Data driven X – Turning Data into Value, P. Drews, B. Funk, P. Niemayer and L. Xie (eds.), Lüneburg. 6. – 9. März 2018, pp. 369–380.
Schäffer, T., and Stelzer, D. 2017. “Assessing Tools for Coordinating Quality of Master Data in Inter-organizational Product Information Sharing,” in Proceedings der 13. Internationalen Tagung Wirtschaftsinformatik (WI 2017), J. M. Leimeister and W. Brenner (eds.), St. Gallen. 12.-15. Februar 2017, St. Gallen, pp. 61–75.
Schäffer, T., and Stelzer, D. 2018. “Barriers to Adopting Data Pools for Product Information Sharing – A Literature Review,” in Multikonferenz Wirtschaftsinformatik (MKWI) 2018: Data driven X – Turning Data into Value, P. Drews, B. Funk, P. Niemayer and L. Xie (eds.), Lüneburg. 6. – 9. März 2018, pp. 295–306.
Scheuch, R., Gansor, T., and Ziller, C. 2012. Master Data Management: Strategie, Organisation, Architektur, Heidelberg: dpunkt.verlag GmbH.
Schuh, Günther; Volker, Stich; Scheibmayer, Marcel, Knapp, Matthias (2014): Stammdatenmanagement in der produzierenden Industrie.
Schuh, Günther;Anderl, Reiner;Gausemeier, Jürgen;ten Hompel, Michael;Wahlster, Wolfgang (2017): Industrie 4.0 Maturity Index – Die digitale Transformation von Unternehmen gestalten.
Wang, R. Y., and Strong, D. M. 1996. “Beyond Accuracy: What Data Quality Means to Data Consumers,” Journal of Management Information Systems (12:4), pp. 5–33.


