
For some time now, Process Mining has been stimulating discussions about the topic of process optimisation in companies. The goal of Process Mining is to discover the actual processes in a company by analysing business data and the digital traces they leave in the company’s IT systems. | Short interview with Prof.dr.ir. Wil van der Aalst, one of the most renowned experts in this area.
 New business models, increasing competitive pressure, internationalisation and digitisation are just some of the challenges companies have to face. Most strategies that companies use to respond to this dynamic environment have one thing in common: they have a tangible impact on business organisation and business processes. Hence, process optimisation has become a permanent issue in companies and different methods and means are being used to make processes faster and more efficient, to streamline and to simplify them. Often, business software (such as ERP systems, workflow or BI solutions) is used in this context.
New business models, increasing competitive pressure, internationalisation and digitisation are just some of the challenges companies have to face. Most strategies that companies use to respond to this dynamic environment have one thing in common: they have a tangible impact on business organisation and business processes. Hence, process optimisation has become a permanent issue in companies and different methods and means are being used to make processes faster and more efficient, to streamline and to simplify them. Often, business software (such as ERP systems, workflow or BI solutions) is used in this context.
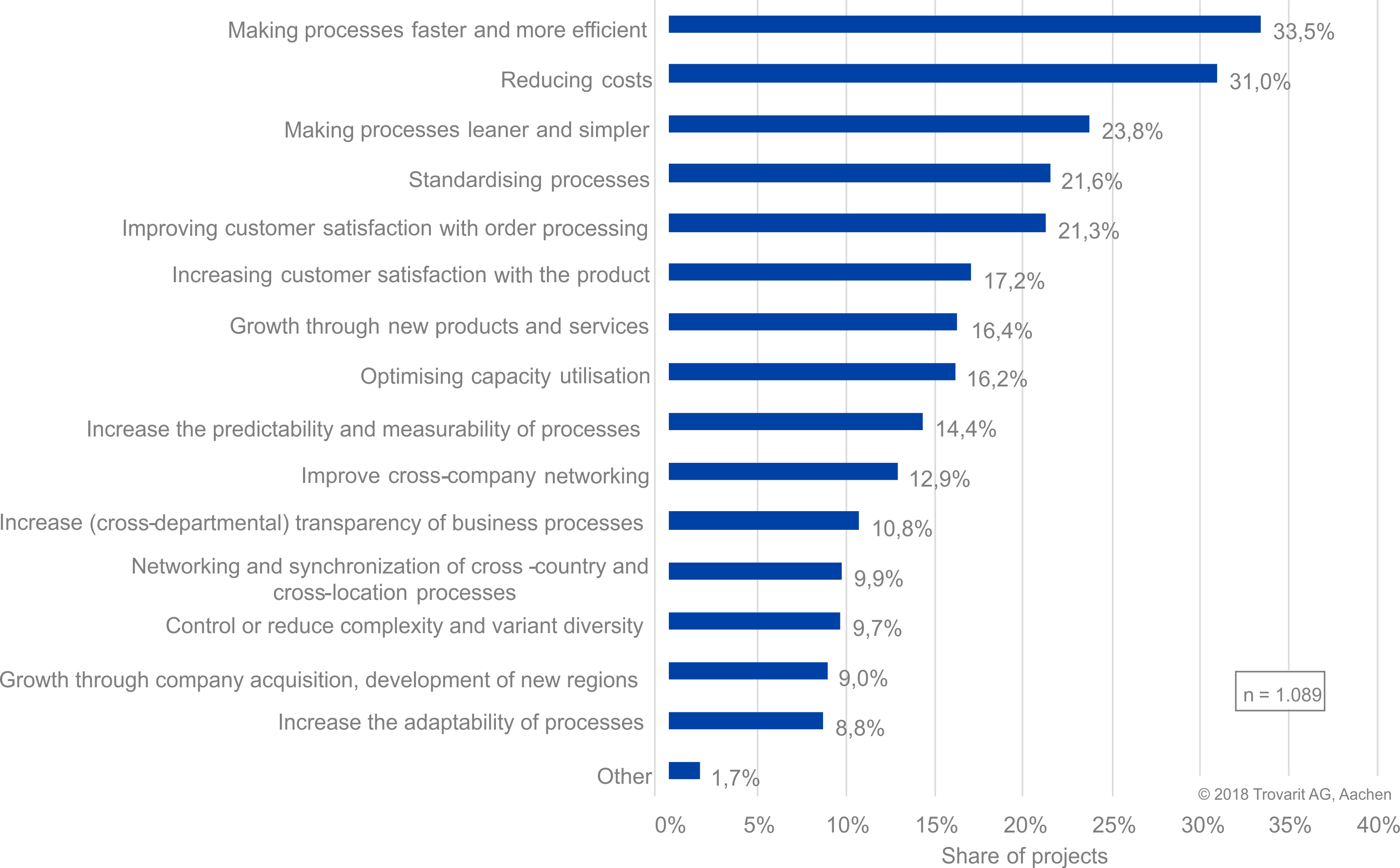
(Source: „ERP in Practice: User Satisfaction, Benefits and Perspectives 2018/2019“)
For some time now, Process Mining has been stimulating discussions about the topic of process optimisation in companies. The goal of Process Mining is to discover the actual processes in a company by analysing business data and the digital traces they leave in the company’s IT systems.
 Prof.dr.ir. Wil van der Aalst has held the Alexander von Humboldt Professorship at RWTH Aachen University since the beginning of 2018. The computer scientist from Eindhoven University of Technology is a proven expert in the fields of Process Mining, Business Process Management, Workflow Management Systems and Data Science. He is one of the most cited scientists in his field and has published over 200 scientific articles, is involved in 500 book and conference publications and has published 20 books as author or editor.
Prof.dr.ir. Wil van der Aalst has held the Alexander von Humboldt Professorship at RWTH Aachen University since the beginning of 2018. The computer scientist from Eindhoven University of Technology is a proven expert in the fields of Process Mining, Business Process Management, Workflow Management Systems and Data Science. He is one of the most cited scientists in his field and has published over 200 scientific articles, is involved in 500 book and conference publications and has published 20 books as author or editor.
The interview
Benesch: Process mining draws on „Big Data“, on a large number of event logs that map the individual cases and can be analysed with regard to the actual processes. What requirements does process mining place on a company’s business software infrastructure? Do the software solutions used (ERP, CRM, ECM, etc.) have to meet certain requirements with regard to data structures, interfaces, etc.?
van der Aalst: Event data are everywhere. However, they need to be extracted and converted into event logs ready for analysis. An event log ‚views‘ a process from a particular angle. Each event in the log refers to (1) a particular process instance (called case), (2) an activity, and (3) a timestamp. There may be additional event attributes referring to resources, people, costs, etc., but these are optional. Hence, the requirements are minimal. Often the challenge is to identify the case notion to be used. This can be an order number in an SAP system, a patient number in a healthcare information system, the identifier of a suitcase checked in at an airport, etc. All ERP, CRM, and ECM systems provide a wealth of event data. However, depending on the process to be analyzed one needs to locate and transform the data. For standard processes such as the Purchase-to-Pay (P2P) and Order-to-Cash (O2C), this has been done many times before and one can benefit from experiences of others (e.g., standard adapters and best practices). However, systems like SAP have tens of thousands of tables and many organizations have different software packages and configurations specific for the organization. Hence, in general, it is not so easy to locate the data relevant for a specific process. However, once the data are located and extracted it is easy to apply process mining. In initial process mining projects, 80% of the time is spent on data extraction and only 20% on the actual analysis. However, when using process mining continuously, this is just an initial hurdle after which one can focus on the daily or weekly analysis and improvement of processes.
Benesch: In one of your articles[1] you describe Philips Healthcare as a use case for process mining. The company manages and maintains most of its customers‘ medical equipment via the Internet and generates 22.5 million events per day with its cardiology systems alone. In other words, a medical technology company with around 78,000 employees worldwide that monitors its products throughout their entire life cycle. How does a company have to be positioned for process mining to make sense? Is a certain process characteristic (e.g. highly standardized, high number of cases, etc.) a prerequisite? Are there industries or company sizes that are typically predestined as Use Cases for Process Mining due to the evaluable event data quantities?
van der Aalst: Philips is one of many organizations applying process mining. I like to compare process mining to our good old spreadsheet technology. Spreadsheets can be viewed as an ultimate success story. Most computers in the world have a program like Excel installed and spreadsheets are used in any organization. Note that spreadsheet software is generic and can be used in any organization. It would not make sense to have a separate version of Excel for hospitals, schools, or shops, just like it would not make any sense to have different versions of Word for different types of organizations. Spreadsheets can be used to do anything with numbers, but are unable to handle process models and event data. Process mining technology is similar to Excel, but rather than focusing on numbers, it focuses on events. Process mining can do anything with events. It can discover the real processes, detect deviations from normative process models, and analyze and predict bottlenecks and waste. Comparable to spreadsheet programs like Excel which are widely used in finance, production, sales, education, mobility, and health, process mining software can be used in a broad range of organizations. I am still fascinated by the broad range of organizations using process mining. Companies like BMW, Siemens, REWE, ING, Vodafone, DHL, Lufthansa, Vanderlande, Heineken, Uber, Telekom, Telfonica etc. are using process mining to improve processes in logistics, manufacturing, finance, healthcare, customer relationship management, and communication. Any organization can use process mining, and the prerequisites are minimal. Most organizations start with the Purchase-to-Pay (P2P) and Order-to-Cash (O2C) processes, but this is just one of many possible starting points. Of course, process mining can be applied most easily when processes are standardized and have many instances (i.e., cases). However, for less structured processes, the possible improvements may be even larger. What is important for the successful application of process mining is that the organization has a „data-science mindset“.
Benesch: A process mining tool delivers the final result of a representation of the business processes (process model) as they actually run. Apart from obvious errors and deviations from the best possible way of processing a task, order etc., what are the potential benefits of such process models for companies? What is the relationship between the benefits and expenses (financial/personnel) for software, implementation and operation of a process mining tool?
van der Aalst: Process mining reveals performance and compliance problems. By making these transparent, processes can be improved (e.g., reducing costs, improving quality, and removing delays). Although the advantages are obvious, management often expects a „business case“ showing the Return on Investment (RoI). This is often slowing down the adoption of process mining. I consider process mining to be comparable to „personal hygiene“: It is something that one simply needs to do! Although it is not easy to make a clear „business case“ for „personal hygiene“, not doing it increases the risk of getting and spreading a range of diseases. Organizations not using process mining are, most likely, not aware of their actual processes and problems. Similar to personal hygiene, one should not need to argue in favor of process mining. Therefore, it is important to start process mining on a larger scale and not as a small „toy project“. Process mining should be done continuously and for many processes (rather than a pilot project doing one analysis on one process at a given time). Since data extraction is time-consuming, one should do this only once, but do it in such a way that it can be applied continuously using the latest event data. In general, one can say that there are two possible inhibitors: (1) people and (2) data.
1. People may be unaware of the possibilities provided by process mining. Six Sigma experts do not know process mining or see it as a competing methodology. Process managers, BPM consultants, auditors, and accountants may not be eager to learn a new technology. Professionals need to step out their comfort zones and embrace the new possibilities. Moreover, middle management may not want the transparency provided by process mining. Using conformance checking, one may find that 40% of the cases are deviating from the normative process. This is not always a welcome message. People tend to use fake arguments related to privacy and data quality to avoid the much-needed transparency in processes.
2. Process mining often reveals major data quality problems. It may be time-consuming to collect event data and, the moment the first process mining results are presented, it becomes clear that data are missing, incorrect, duplicated, etc. This is no reason to stop doing process mining. However, it should be a trigger to improve data management. When making the „business case“ for process mining, once should not include the „costs for getting the data right“. Organizations need to have the right data in order to survive in the long run.
The inhibitors for process mining just mentioned are still there, but will also slowly disappear in the coming years. There will be new generations of professionals trained in data science. These will know about process mining and will not accept bad data-management practices.
Benesch: The topic of process mining is not really new, but it seems to have gained a lot of interest in the last one to two years. Which trends or conditions are currently acting as drivers of process mining? What prospects do you see for „process mining in the large“?
van der Aalst: I started to work on process mining in the late 1990-ties. My students started to create process-mining companies over a decade ago. Hence, for me personally, it has taken a long time (over 20 years) to get to the point where we are now. But indeed, the speed of adoption is increasing in recent years. There are over 30 process-mining vendors and accounting firms like KPMG, EY, Deloitte, and PwC are offering process mining as a service. Process mining has reached a critical mass and is increasingly used in conjunction with other technologies like Robotic Process Automation (RPA). Process mining is clearly changing from a „data-science tool for experts“ to a platform used by many in the organization in a continuous manner. Consider, for example, Siemens which has over 6000 active Celonis users analyzing hundreds of operational processes. Siemens saved millions of Euros by reducing rework, process unification, etc. These 6000 process mining users use process mining results continuously without having to understand the underlying technology.
Just like the weather radar and forecast, process mining should show current performance and compliance diagnostics and predict what will happen without interventions. Information should be interpretable by end-users and actionable (e.g., support decision-making, corrective actions, and process redesign). Organizations cannot influence the weather, but they can influence the way processes are executed. Such „forward-looking“ forms of process mining will increase adoption.
Next to „forward-looking“ forms of process mining, I see a convergence of traditional process modeling and process mining. There is still a gap between the BPMN models made with tools such as Signavio, Bizagi, ARIS, iGrafx, and Camunda, and the process models generated using process mining. There should be more „hybrid“ process modeling notations supporting both modeling and mining in a seamless manner. Using comparative process mining one would like to project findings on process models end-users can understand. Since these findings are data-driven, different stakeholders will be interested, thus enabling „process mining in the large“.
[1] W.M.P. van der Aalst. Process Mining in the Large: A Tutorial. In E. Zimanyi, editor, Business Intelligence (eBISS 2013), volume 172 of Lecture Notes in Business Information Processing, pages 33-76. Springer-Verlag, Berlin, 2014.
About the author
 Claudia Benesch is head of communications at Trovarit AG and editor in chief of the business software magazines
Claudia Benesch is head of communications at Trovarit AG and editor in chief of the business software magazines
IT-Matchmaker.guide.


